Receipts to show on screen
The source stack
Start with the public artifacts, then explain the missing nuance: loops need real triggers, reviewable output, and bounded judgment.
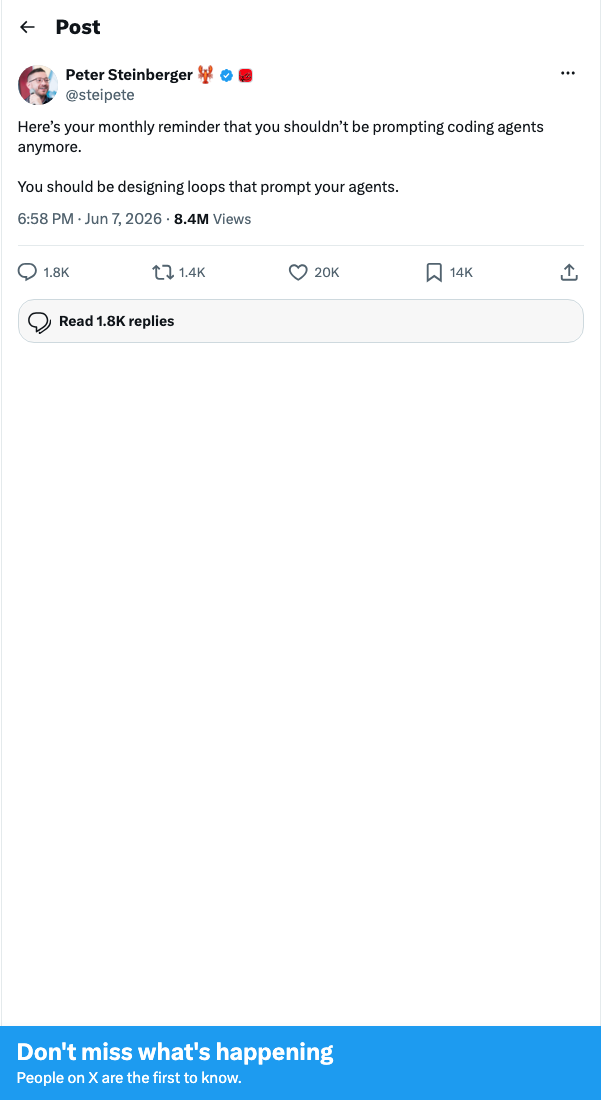
Peter Steinberger tweet
Stop prompting agents directly. Design loops that prompt them.
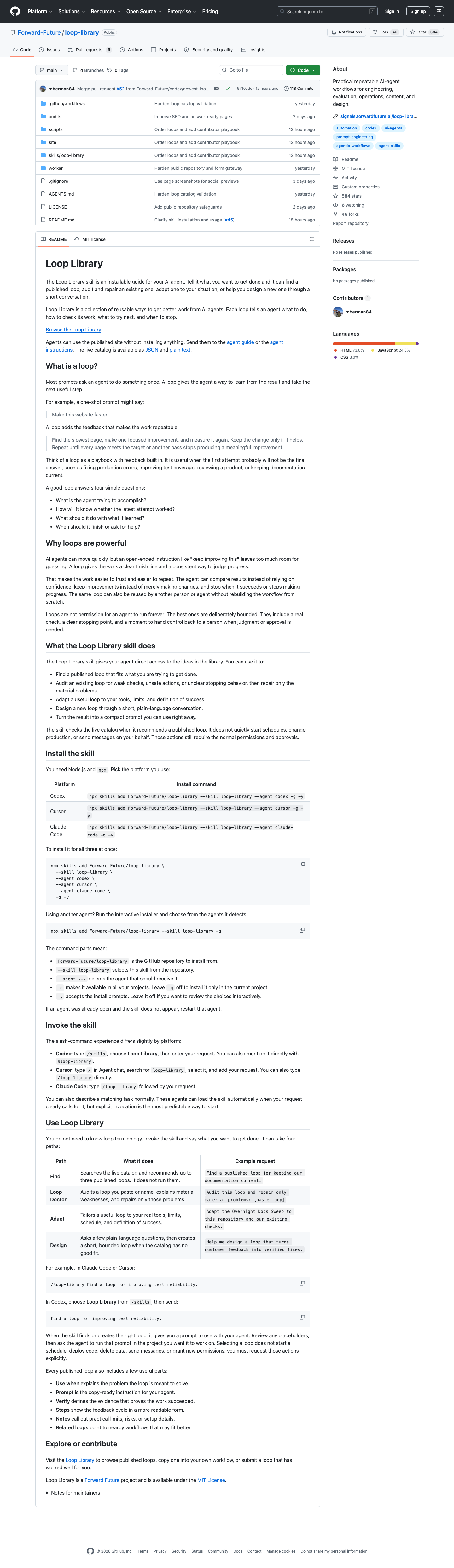
Loop Library repo
Reusable loop prompts with checks, next steps, and stop conditions.
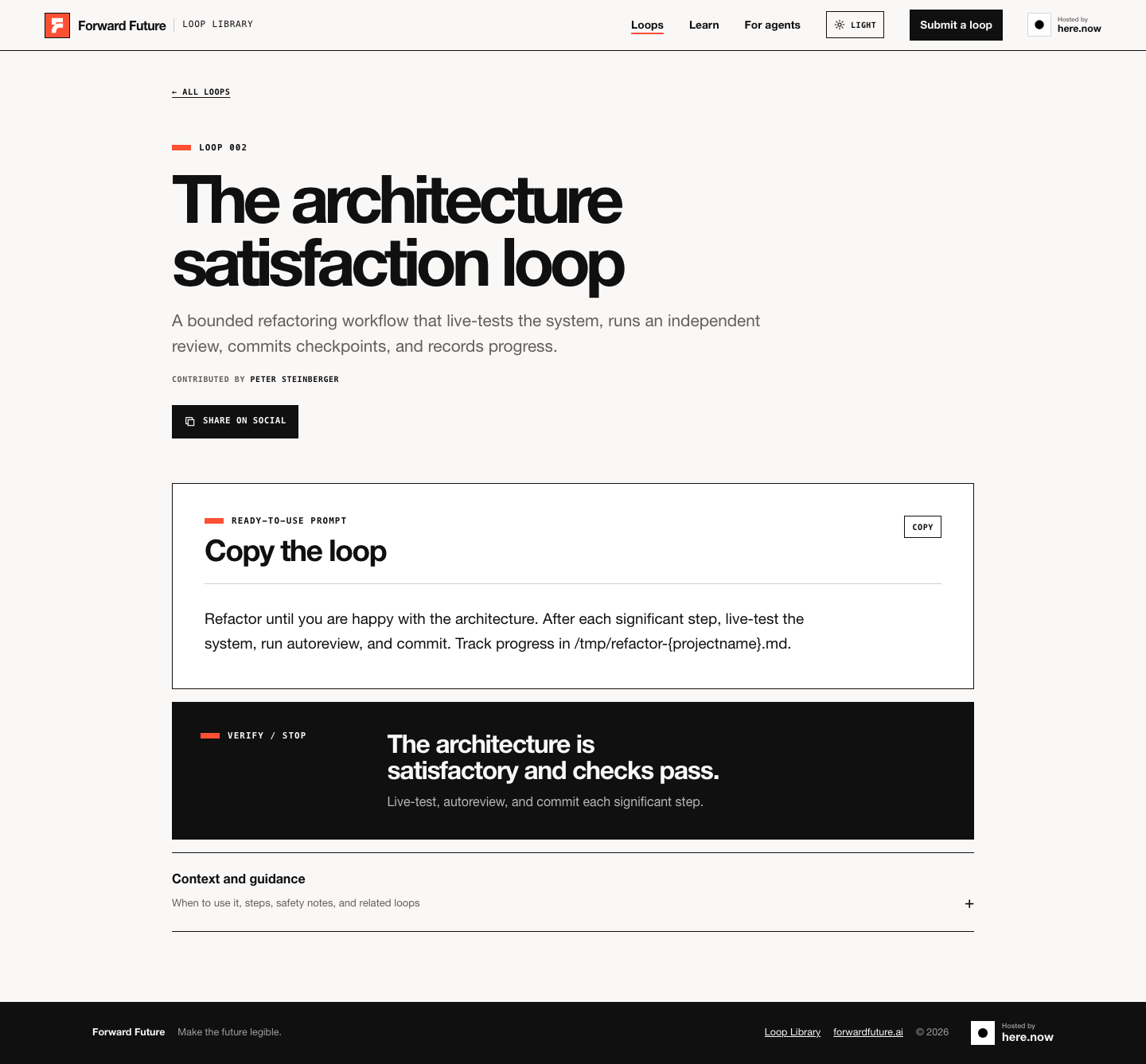
Architecture satisfaction loop
Useful, but the stopping rule depends on judgment.

ClawSweeper
Issues and PRs create a recurring surface for an agent to scan.
Where loops work
Production creates real triggers.
Peter Steinberger's OpenClaw/ClawSweeper setup makes sense because issues, PRs, stale work, and review queues keep appearing. The loop has a real reason to wake up.
Where loops are overkill
Fake triggers are procrastination.
If you are an individual builder and you already know the next step, you probably do not need a loop. You need to do the work. The loop becomes useful when similar work keeps returning.
The hard part
Evaluators are still fuzzy.
A lot of loops stop when the result feels good enough. That can work for architecture and creative review, but it is not the same as a production metric.